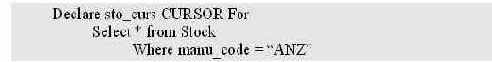Необходимость организации параллельной работы с базами данных обусловлена необходимостью разделять одну базу данных несколькими пользователями одновременно. Поэтому, как в любой системе управления параллельной деятельностью, необходимы механизмы упорядочения доступа к ограниченному разделяемому ресурсу со стороны множества параллельных процессов. В процессе организации параллельной работы решаются задачи по достижению двух целей:
установить все блокировки, необходимые для обеспечения целостности данных;
уменьшить, по возможности, число и размеры блокируемых фрагментов, не входя в противоречие с первой целью.
Рассмотрим простейшую ситуацию параллельного выполнения двух программ.
Программа I выбирает строки таблицы базы данных через курсор.
Программа II выполняет обновление тех же строк таблицы.
Возможны следующие четыре варианта последствий, известные как эффекты параллелизма.
Вторая программа заканчивает обновление строк до того, как первая программа выбирает первую строку. В этом случае первая программа показывает только обновленные строки.
Первая программа успевает выбрать каждую строку прежде, чем вторая программа получает возможность ее обновить. В такой ситуации первая программа показывает только исходные строки.
После того, как первая программа выбрала некоторое количество исходных строк, вмешивается вторая программа и приступает к корректировке тех строк, которые первая программа еще не прочитала, и после этого выполняет оператор Commit Work. В этом случае результатом первой программы может быть смесь исходных и обновленных строк.
Случай, аналогичный варианту 3, за исключением того, что после корректировки таблицы вторая программа выполняет оператор Rollback Work. Результатом работы первой программы в этом случае может быть смесь исходных и обновленных строк, которых больше нет (а точнее и не существовало) в базе данных.
Если первые две ситуации вполне безобидные, то две последние (особенно четвертая) не оправданы ни с позиции логики, ни с позиции здравого смысла.
Выделяют два класса параллельности. Первый класс применим в отношении доступа к базе данных на чтение (Select) и называется уровнем изоляции. Второй класс параллельности распространим на операции, модифицирующие базу данных (Insert, Delete, Update).