Payment
На рис. 5 (слева) показано уменьшение числа команд, затрачиваемых на выполнение транзакции Payment, за счет оптимизации сравнения ключей B-дерева и удаления функциональности журнализации, блокировок, защелок и менеджера буферов. В правой части рисунка для каждого действия по оптимизации или удалению компонентов показано его воздействие на число команд, затрачиваемых на разные части выполняемой транзакции. Для транзакции Payment эти части включают вызов метода начала транзакции, три поиска в B-дереве, три соответствующих операции pin/unpin, три операции модификации (через B-дерево), одно создание записи и вызов метода фиксации транзакции. Высота каждого прямоугольника соответствует общему числу выполненных команд. Самый правый прямоугольник показывает производительность ядра с минимальными накладными расходами.
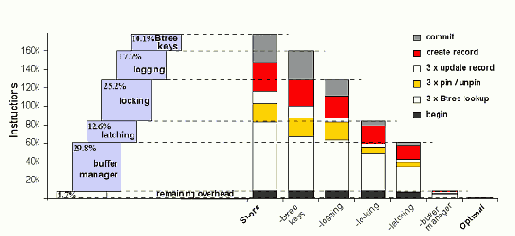
Рис. 5. Детальный анализ числа команд для транзакции Payment
По имеющейся у авторов информации, выполненная ими оптимизация сравнения ключей B-дерева является стандартной практикой в высокопроизводительных архитектурах СУБД, и для Shore эта оптимизация была произведена первой, поскольку ее следует делать в любой системе.
Удаление журнализации влияет, главным образом, на операции фиксации транзакций и модификации, поскольку именно в их коде генерируются журнальные записи; в меньшей степени это действие затрагивает поиск в B-деревьях и каталогах. Произведенные модификации позволили сократить общее число команд на 18%.
На поддержку блокировок тратится около 25% от общего числа команд. Удаление блокировок влияет на весь код, но в особенности на операции pin/unpin, поиска в B-деревьях и каталогах, а также фиксации транзакций, т.е. на операции, устанавливающие и освобождающие блокировки (транзакция всегда имеет требуемые блокировки модифицируемых записей к моменту выполнения операций модификации).
Механизм защелок занимает примерно 13% от общего числа команд, и он, прежде всего, затрагивает части транзакций, создающие запись и производящие поиск в B-дереве.
Это связано с тем, что буферный пул (используемый при создании записи) и B-деревья являются основными общими структурами данных, при доступе к которым должна производиться синхронизация.
Наконец, модификации, относящиеся к буферному пулу, позволили сократить общее число команд еще на 30%. Как говорилось ранее, после выполнения этих модификаций память под новые записи получается непосредственно вызовом функции malloc, и в большинстве случаев поиск страниц не проходит через буферный пул. Это делает операцию создания новой записи очень дешевой, а также существенно улучшает производительность других компонентов, часто осуществляющих поиск.
К этому моменту в оставшемся ядре выполняется 5% от исходного числа команд (что дает двадцатикратный выигрыш в производительности), что в шесть раз превышает число выполняемых команд в «оптимальной» системе. Этот анализ приводит к двум наблюдениям. Во-первых, существенны все шесть основных компонентов, для каждого требуется выполнение не менее 18 тысяч команд из исходных 180 тысяч. Во-вторых, до применения всех оптимизаций сокращение числа выполняемых команд не является слишком существенным: до последнего шага по удалению менеджера буферов в оставшихся компонентах выполняется примерно треть от исходного числа команд (а после удаления менеджера буферов достигается 20-кратное повышение пропускной способности).
