Результаты
На рис. 1 показано, как эти модификации влияют на итоговую производительность Shore (измеряемую числом выполненных команд центрального процессора на транзакцию New Order из TPC-C). Как можно видеть, каждая из этих подсистем занимает от 10 до 35% общего объема работы системы (1.73 миллиона команд, соответствующих общей высоте рисунка).
«Оптимизации, произведенные вручную» здесь представляют набор оптимизаций, которые были внесены в код авторами и направлены, прежде всего, на улучшение эффективности пакета для работы с B-деревьями. Реальные команды, обрабатывающие данный запрос и называемые на рисунке «полезной работой», – это команды минимальной реализации, выполненной авторами поверх вручную закодированного пакета поддержки B-деревьев в основной памяти. Число команд минимальной реализации при выполнении запроса составляет около одной шестидесятой от общего числа выполненных команд исходной системы. Белый прямоугольник под «buffer manager» представляет версию Shore после того, как из системы было удалено все, что было возможно, – в ней все еще выполняются транзакции, но используется около 1/15-ой от числа команд исходной системы, или в четыре раза больше числа команд полезной работы. Дополнительный выигрыш, обеспечиваемый минимальной реализацией, объясняется глубиной стека вызовов в Shore и тем фактом, что авторы не смогли полностью избавиться в Shore от всего наследия транзакций и менеджера буферов.
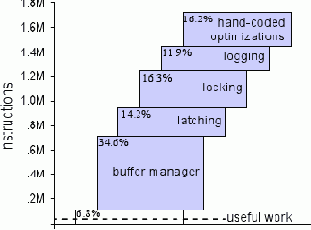
Рис. 1. Анализ выполнения команд в разных подсистемах СУБД для транзакции New Order из TPC-C. Верхняя часть столбиковой диаграммы соответствует производительности исходной системы Shore при поддержке всей базы данных в основной памяти и отсутствии конкуренции между потоками. Нижняя пунктирная линия – это полезная работа, измеренная путем выполнения той же транзакции на ядре без накладных расходов
